# LogBus User Guide
This section mainly introduces the use of the data transmission tool LogBus:
LogBus Windows Version Please read the LogBus Windows Version User Guide
Before starting the docking, you need to read the data rules first. After you are familiar with the data format and data rules of the TA, read this guide for docking.
LogBus upload data must follow TA's data format
# Download LogBus
The latest version is : 1.5.15.7
Updated : 2021-12-10
Download address (opens new window)
Linux arm version download address (opens new window)
Version upgrade instructions:
- Version 1.5.0 and above:
First execute ./logbus stop command to stop LogBus, and then execute ./logbus update command to upgrade to the latest version.
- If you are using a version before 1.5.0 and need to upgrade to a new version, please contact TA staff.
# I. Introduction to LogBus
The LogBus tool is mainly used to import the back-end log data into the TA background in real time. Its core working principle is similar to Flume. It will monitor the file flow under the server log directory. When any log file under the directory has new data, it will verify the new data and send it to the TA background in real time.
The following categories of users are recommended to use LogBus to access data:
- Users using the server level SDK, upload data via LogBus
- High requirements for data accuracy and dimensions, only through the client side SDK can not meet the demands for data, or inconvenient access to the client side SDK
- Don't want to develop your own back-end data push process
- Need to transfer large quantities of historical data
# II. Data Preparation Before Use
First, the data that needs to be transferred is converted into the data format of TA by ETL, and written locally or transmitted to the Kafka cluster. If the server level SDK is used to write local files or Kafka consumers, the data is already The correct format does not need to be converted.
Determine the directory where the uploaded data files are stored, or the address and topic of Kafka, and configure the relevant configuration of LogBus. LogBus will monitor the file changes in the file directory (monitor the new file or tail the existing file), or subscribe to the data in Kafka.
Do not rename the data logs stored in the monitoring directory and uploaded directly. Renaming the logs is equivalent to creating new files. LogBus may upload these files again, causing data duplication.
Since the LogBus data transfer component contains data buffers, the LogBus directory may take up slightly more disk space, so please ensure that the LogBus installation node has sufficient disk space, and at least 10G of storage space should be reserved for each data transfer to an item (that is, an additional APP_ID).
# III. Installation and Upgrade of LogBus
# 3.1 Install LogBus
Download the LogBus compressed package (opens new window)and decompress it.
Unzipped directory structure:
Bin: Launcher folder
Configuration file folder
Lib: function folder
# 3.2 Upgrade LogBus
If you are using 1.5.0 and later versions, you can use the ./logbus stop command to stop LogBus , then execute the./logbus update command to upgrade LogBus to the latest version, and then restart LogBus.
# 3.3 docker version
If you need to use logbus in the docker container, please refer to the LogBus docker usage guide (opens new window)
# IV. Parameter Configuration of LogBus
Enter the unzipped
confdirectory, which has a configuration filelogB us.conf. Template, which contains all the configuration parameters of LogBus, and can be renamed tologB us.confwhen used for the first time.Open the
logB us.conffile for relevant parameter configuration.
# 4.1 Project and Data Source Configuration (Must Be Configured)
- Project APP_ID
##APPID is from token on TGA website. Please get the APPID of the accessing project from the project configuration page in TA background and fill it in here. Multiple APPIDs are split by''.
APPID=APPID_1,APPID_2
- Monitor file configuration (please select one, must be configured).
# 4.1.1. When the data source is a local document
The path and file name of the data file read by ##LogBus (file name supports ambiguous matching) requires read permission
##Different APPIDs are separated by commas, while different directories of the same APPID are separated by spaces
##TAIL_ FILE file name supports both regular expression and wildcard modes of the Java standard
TAIL_ FILE=/path1/dir*/log. * / Path 2/DATE {YYYYMMDD}/txt. *,/ Path3/txt. *
##TAIL_ MATCHER Specifies TAIL_ Fuzzy matching mode regex-regular glob-wildcard for FILE path.
##regex is a regular mode that supports regular expressions using the Java standard, but only supports one level of fuzzy matching of directory and file names
##glob is wildcard mode and supports multi-layer directory fuzzy matching and does not support matching in DATE{}format
##Defaults to match using regex regular expressions
#TAIL_ MATCHER=regex
TAIL_FILE supports monitoring multiple files in multiple subdirectories under multiple paths. The following figure is
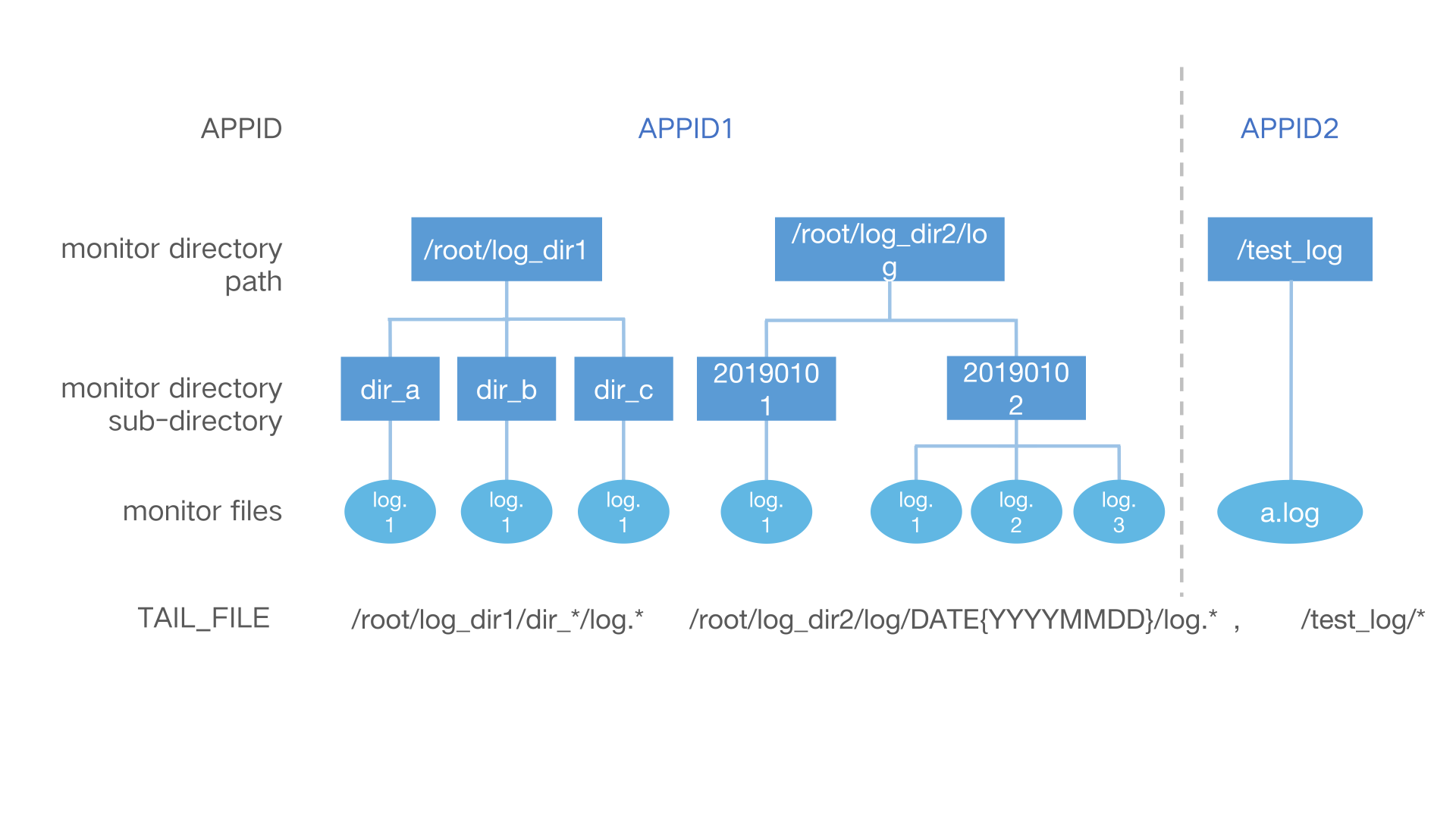
The corresponding parameters are configured as:
APPID=APPID1,APPID2
TAIL_FILE=/root/log_dir1/dir_*/log.* /root/log_dir2/log/DATE{YYYYMMDD}/log.*,/test_log/*
The specific rules are as follows:
- Multiple monitoring paths in the same APP_ID are divided by spaces
- The monitoring paths of different APP_ID are divided by half-angle commas , and the monitoring paths correspond to each other after being divided by commas APP_ID
- The sub-directories in the monitor path (that is, the directory where the file is located) support date format, regular expression monitoring or wild-card matching
- Filename support using regular expression monitoring or wild-card
Do not store log files that need to be monitored in the server root directory.
Rules for date format catalogs (only supported by regex mode):
Date format catalog to DATE {} enclosed date templates, DATE must be capitalized , the following examples of several identifiable date templates and file samples corresponding to the monitoring, but not limited to this, date templates only need to be standard date format.
/root/logbus_data/DATE{YYYY-MM-DD}/log.*---> /root/logbus_data/2019-01-01/log.1/root/logbus_data/DATE{YYMMDD}/log.*---> /root/logbus_data/190101/log.1/root/logbus_data/DATE{MM_DD_YYYY}/log.*---> /root/logbus_data/01_01_2019/log.1/root/logbus_data/DATE{MMDD}/log.---> /root/logbus_data/01*01/log.1
# 4.1.2. When the data source is kafka
Since version 1.5.2, the parameters KAFKA_TOPICS no longer support regular expressions. When multiple topics need to be monitored, you can use spaces to separate each topic; if there are multiple APP_ID, use half-corner commas to separate the topics monitored by each APP_ID. The parameter KAFKA_GROUPID must be unique. The 1.5.3 version adds KAFKA_OFFSET_RESET parameters, which can set the kafka.consumer.auto.offset.reset parameters of Kafka. The preferred values are earliest and latest , and the default setting is earliest .
Note: The Kafka version of the data source must be 0.10.1.0 or higher
Single APP_ID example:
APPID=appid1
######kafka configure
#KAFKA_GROUPID=tga.group
#KAFKA_SERVERS=localhost:9092
#KAFKA_TOPICS=topic1 topic2
#KAFKA_OFFSET_RESET=earliest
#Optional Cloud Service Provider:tencent/ali/huawei
#KAFKA_CLOUD_PROVIDER=
#KAFKA_INSTANCE=
#KAFKA_USERNAME=
#KAFKA_PASSWORD=
#SASL certificate
#KAFKA_JAAS_PATH=
#KAFKA_SECURITY_PROTOCOL=
#KAFKA_SASL_MECHANISM=
Multiple APP_ID examples:
APPID=appid1,appid2
######kafka configure
#KAFKA_GROUPID=tga.group
#KAFKA_SERVERS=localhost:9092
#KAFKA_TOPICS=topic1 topic2,topic3 topic4
#KAFKA_OFFSET_RESET=earliest
#Optional Cloud Service Provider:tencent/ali/huawei
#KAFKA_CLOUD_PROVIDER=
#KAFKA_INSTANCE=
#KAFKA_USERNAME=
#KAFKA_PASSWORD=
#SASL certificate
#KAFKA_JAAS_PATH=
#KAFKA_SECURITY_PROTOCOL=
#KAFKA_SASL_MECHANISM=
# 4.2 Configuration of Transmission Parameters (Must Be Configured)
##Transfer Setting
##Transmitted url
##For HTTP transmission use the
PUSH_URL=http://receiver.ta.thinkingdata.cn/logbus
##If you are using a self-hosting deployment service, modify the transfer URL to: http://Data Acquisition Address/logbus
##Check appid on or off by default
#IS_CHECK_APPID=false
##Maximum number per transmission
#BATCH=10000
##How often should it be transmitted at least once (in seconds)
#INTERVAL_SECONDS=600
##Number of transfer threads, actual threads + 1 of configuration threads, default two threads
#NUMTHREAD=1
##Do you add UUID attributes to each data item (opening reduces transmission efficiency)
#IS_ADD_UUID=true
##Compressed formats for file transfer: gzip, lzo, lz4, snappy, none
#COMPRESS_FORMAT=none
# 4.3 Flume Memory Parameter Configuration (Optional Configuration)
# Flume Piping Capacity Setting
# Pipeline capacity, which depends on the configuration of the deployed computer.
CAPACITY=1000000
# Pipeline to sink transmission volume, greater than BATCH parameters
TRANSACTION_CAPACITY=10000
##Specify the maximum memory flume starts in M.
#MAX_MEMORY=2048
# Channel settings for flume, file and memory (optional, file is used by default)
# CHANNEL_TYPE=file
# 4.4 Monitoring File Deletion Configuration (Optional Configuration)
#Monitor directory file deletion and remove comments to start the delete file function
#can only be deleted by day or hour
# UNIT_ REMOVE=hour
#Delete how long ago
# OFFSET_ REMOVE=20
#Delete uploaded monitoring files every few minutes
# FREQUENCY_ REMOVE=60
# 4.5 Custom Parser (Optional Configuration)
Version 1.5.9 begins to support customer-defined data parsers, which are used to customize the conversion format when the original data format is inconsistent with the TA data format.
Details are as follows:
- Add the following dependencies
Maven:
<dependency>
<groupId>cn.thinkingdata.ta</groupId>
<artifactId>logbus-custom-interceptor</artifactId>
<version>1.0.3</version>
</dependency>
Gradle:
// https://mvnrepository.com/artifact/cn.thinkingdata.ta/logbus-custom-interceptor
compile group: 'cn.thinkingdata.ta', name: 'logbus-custom-interceptor', version: '1.0.3'
- Implement the transFrom method in the CustomInterceptor interface. The first parameter in the method is the original data content, and the second parameter is sourceName (used when APP_ID need to be distinguished. According to APP_ID, for example, only one APP_ID is configured, sourceName is r1, if multiple APP_ID are configured, sourceName is r1, r2, etc.).
public interface CustomInterceptor {
TaDataDo transFrom(String var1, String var2);
}
For example, the interface method implemented:
public TaDataDo transFrom(String s, String s1) {
return JSONObject.parseObject(s, TaDataDo.class);
}
- Just configure the following two fields
The two fields below ## are for using a custom parser (both fields must be set before they can be used)
##Custom parser fully qualified name (package name + class name), use default parser if not set
#CUSTOM_ INTERCEPTOR=cn. Thinkingdata. Demo. DemoCustom Interceptor
Absolute path to ##custom parser jar (including jar package file name)
#INTERCEPTOR_PATH=/var/interceptor/custom-interceptor-1.0-SNAPSHOT.jar
# 4.6 Based on #app_in the Data ID for Project Partition (Optional Configuration)
Note: This feature requires TA version 3.1 and above
Add APPID_to version ##1.5.14 IN_ DATA configuration. #app_in used data APPID_can be configured when ID is used for project distribution IN_ DATA=true.
##There is no need to configure APPID at this time, TAIL_ FILE can only be configured on one level.
##Note: TA version requires at least 3.1
#APPID_IN_DATA=false
# 4.7 Automatically Distribute to Corresponding Items According to Configuration (Optional Configuration)
Version # #1.5.14 has changed previous functions and needs to be coordinated with TA3. 1 and above versions.
##Specify the name of the attribute to be mapped, such as name, in conjunction with APPID_ MAP field use
##APPID_ MAP_ ATTRIBUTE_ NAME=name
##Provides a mapping relationship between APPID and attribute values, such as the following configuration when the name field in the properties field representing the data is a or b, the data is distributed to appid_ In 1, when C and D are distributed to appid_ 2
##APPID_ MAP={"appid_1": ["a", ""b"],""appid_2": ["c", ""d"]}
##DEFAULT_ APPID denotes items that are distributed when no name field exists in the data or when the value of the name field is not in the above configuration
##DEFAULT_APPID=appid_3
# 4.8 Sample Configuration File
##################################################################################
## thinkingdata数据分析平台传输工具logBus配置文件
##非注释的为必填参数,注释的为选填参数,可以根据你自身的情况进行
##合适的配置
##环境要求:java8+,更详细的要求请详见tga官网
##http://doc.thinkinggame.cn/tgamanual/installation/logbus_installation.html
##################################################################################
##APPID来自tga官网的token
##不同APPID用逗号隔开
APPID=from_tga1,from_tga2
#-----------------------------------source----------------------------------------
######file-source
The path and file name of the data file read by ##LogBus (file name supports ambiguous matching) requires read permission
##Different APPIDs are separated by commas, while different directories of the same APPID are separated by spaces
##TAIL_ FILE file name supports both regular expression and wildcard modes of the Java standard
#TAIL_ FILE=/path1/log. * / Path2/txt. *,/ Path3/log. * / Path4/log. * / Path5/txt. *
##TAIL_ MATCHER Specifies TAIL_ Fuzzy matching mode regex-regular glob-wildcard for FILE path.
##regex is a regular mode that supports regular expressions using the Java standard, but only supports one level of fuzzy matching of directory and file names
##glob is wildcard mode and supports multi-layer directory fuzzy matching and does not support matching in DATE{}format
##Defaults to match using regex regular expressions
#TAIL_MATCHER=regex
######kafka-source
##kafka,topics Rules of Use
#KAFKA_GROUPID=tga.flume
#KAFKA_SERVERS=ip:port
#KAFKA_TOPICS=topicName
#KAFKA_OFFSET_RESET=earliest/latest
#------------------------------------sink-----------------------------------------
##Transfer Settings
URL transmitted by ##
##PUSH_ URL=http:/${Data Acquisition Address}/logbus
##Maximum number of transmissions per time (data transfer requests sent to a specified number of bars)
#BATCH=1000
##How often should it be transmitted (in seconds) at least (if the number of batches is not met, send the current number)
#INTERVAL_SECONDS=60
##### http compress
##Compressed format for file transfer:gzip,lzo,lz4,snappy,none
#COMPRESS_FORMAT=none
#------------------------------------other-----------------------------------------
##Monitor the deletion of files in the catalog and open the comment (you must open both fields below) to start the delete file function every hour
##Delete files before offet by unit
##Delete how long ago
#OFFSET_ REMOVE=
##Only receive deletions by day or hour
#UNIT_REMOVE=
#------------------------------------interceptor-----------------------------------
The two fields below ## are for using a custom parser (both fields must be set before they can be used)
##Custom parser fully qualified name, use default parser if not set
#CUSTOM_ INTERCEPTOR=
##Custom parser jar location
#INTERCEPTOR_PATH=
# V. Start LogBus
Please check the following before starting for the first time:
- Check the java version
Enter the bin directory, there will be two scripts, check_java and logbus
Where check_java is used to detect whether the java version meets the requirements, execute the script, if the java version does not meet the Java version is less than 1.8 or Can't find java, please install jre first. Wait for the prompt
You can update the JDK version or see the content in the next section to install JDK separately for LogBus
- Install LogBus's independent JDK
If the LogBus deployment node, due to environmental reasons, the JDK version does not meet the LogBus requirements, and cannot be replaced with the JDK version that meets the LogBus requirements. You can use this feature.
Enter the bin directory, there will be install_logbus_jdk.sh .
Running this script will add a new java directory to the LogBus working directory. LogBus will use the JDK environment in this directory by default.
- Complete the configuration of logB us.conf and run the parameter environment check command
For the configuration of logB us.conf, please refer to the Configuring LogBussection
After the configuration is completed, run the env command to check whether the configuration parameters are correct
./logbus env
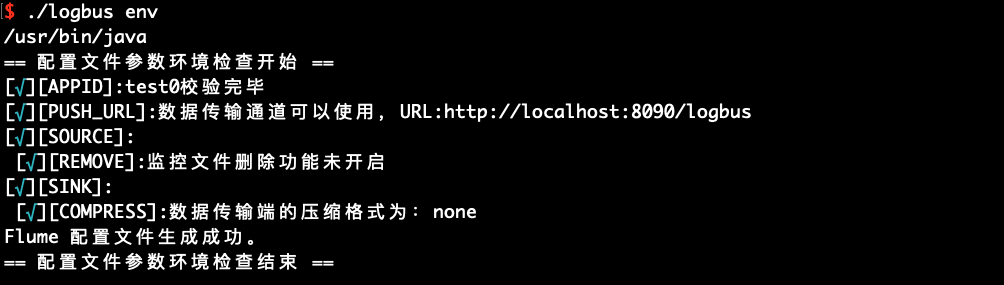
If the red exception information is output, there is a problem with the configuration and it needs to be modified again until there is no exception prompt in the configuration file, as shown in the above figure.
When you modify the configuration of the logB us.conf, you need to restart LogBus for the new configuration to take effect
- Start LogBus
./logbus start
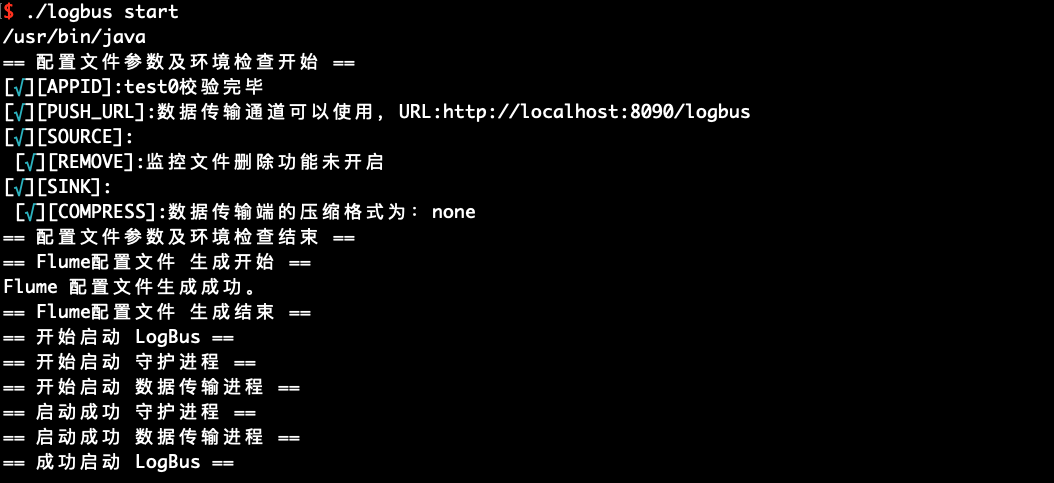
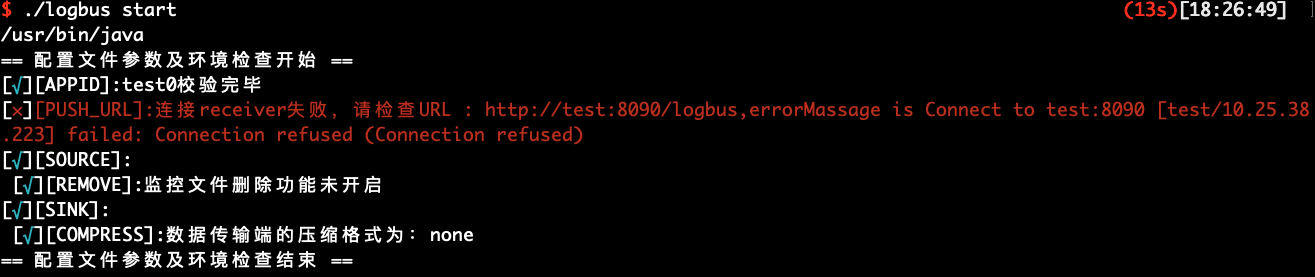
If the startup is successful, there will be a prompt in the above figure, and if it fails, there will be an exception message, as shown in the following figure
# VI. Detailed LogBus Command
# 6.1 Help Information
Without arguments or --help or -h, the following help information will be displayed
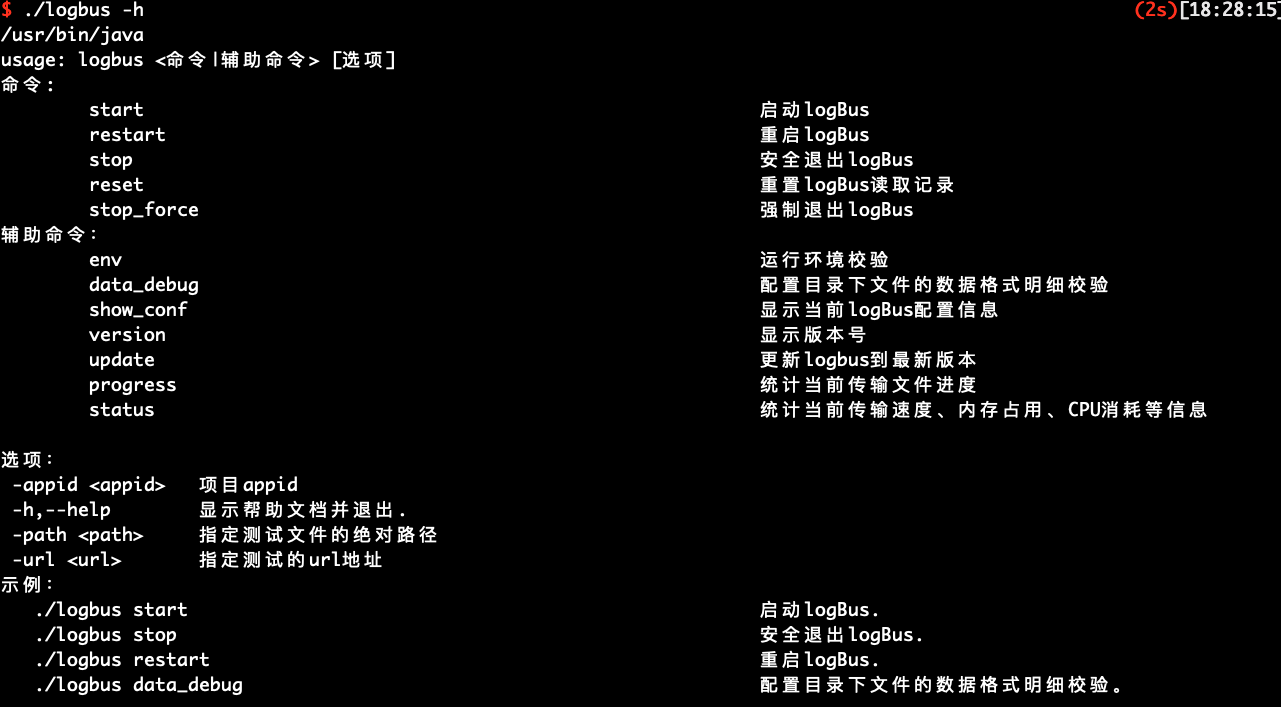
Mainly introduce the commands of LogBus :
usage: logbus <Commands | Auxiliary Commands > [Options]
command:
start Start logBus.
restart Restart logBus.
stop Exit logBus safely.
reset Reset logBus read record.
stop_force Force logBus exit.
Auxiliary Command:
env Run environment check.
data_debug Configure Data Format Details Check for Files in Directory.
show_conf Display current logBus configuration information.
version Display version number.
update Update logbus to latest version.
progress Statistical progress of current transferred files
status Statistics of current transmission speed, memory occupancy, CPU consumption, etc.
Option:
-appid <appid> project appid
-h,--help Display Help Document and Exit.
-path <path> Specify the absolute path to the test file
-url <url> Specify the URL address for the test
Examples:
./logbus start Start logBus.
./logbus stop Exit logBus safely.
./logbus restart Restart logBus.
./logbus data_debug Data Format Verification of Files under Configuration Catalog.
# 6.2 File Data Format Check data_debug
When you use LogBus for the first time, we recommend that you perform format verification on your data before officially uploading the data. The data must conform to the data format specification. You can use the data_debug command to perform data format verification, as follows:
This function will consume cluster resources, with a limit of 10,000 items at a time. Each file will be equally divided and checked first from the file header.
./logbus data_debug
When the data format is correct, the data will be prompted to be correct, as shown in the following figure:
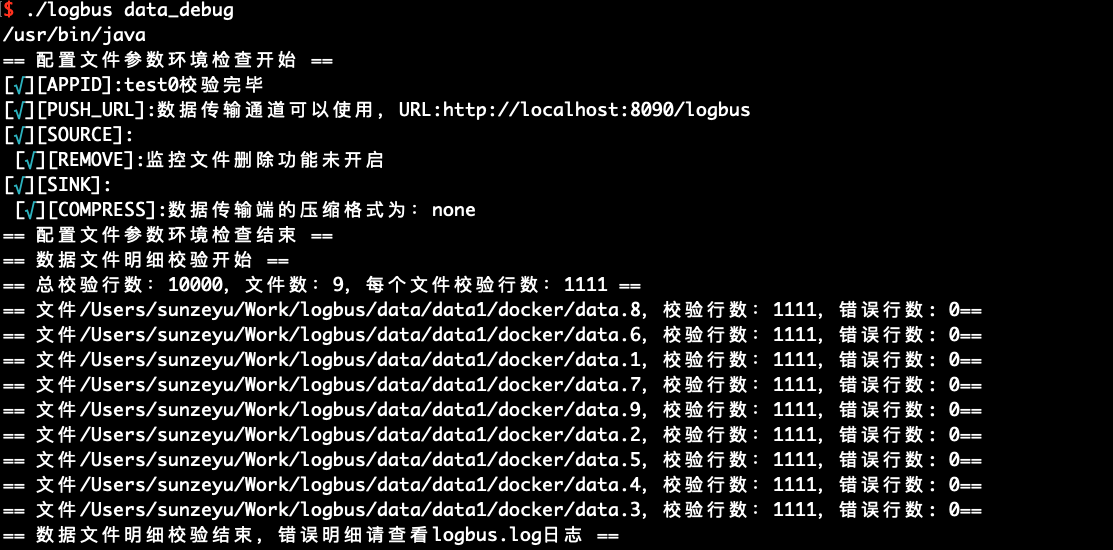
If there is a problem with the data format, it warns of the format error and briefly describes the error point of the format:
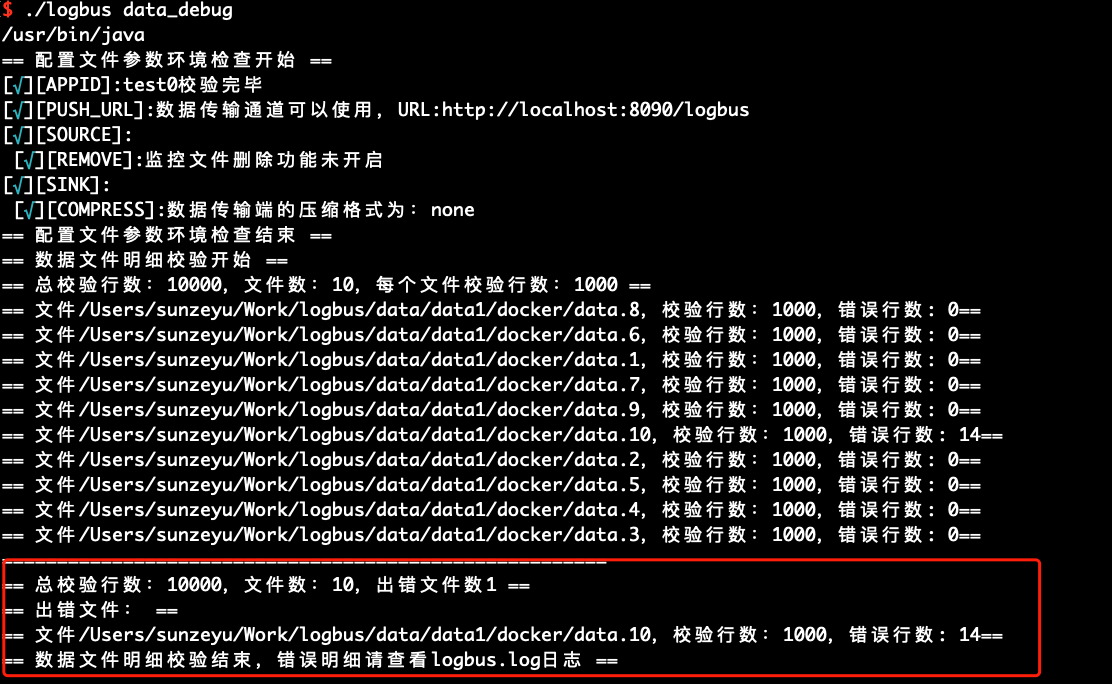
# 6.3 Display Configuration Information show_conf
You can use the show_conf command to view the configuration information of LogBus, as shown in the following figure:
./logbus show_conf
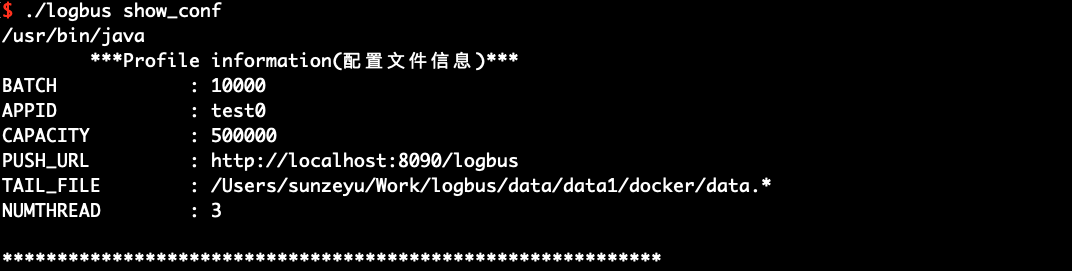
# 6.4 Start Environment Check env
You can use env to check the startup environment. If the output information is followed by an asterisk, it means that there is a problem with the configuration and you need to modify it again until there is no asterisk prompt.
./logbus env
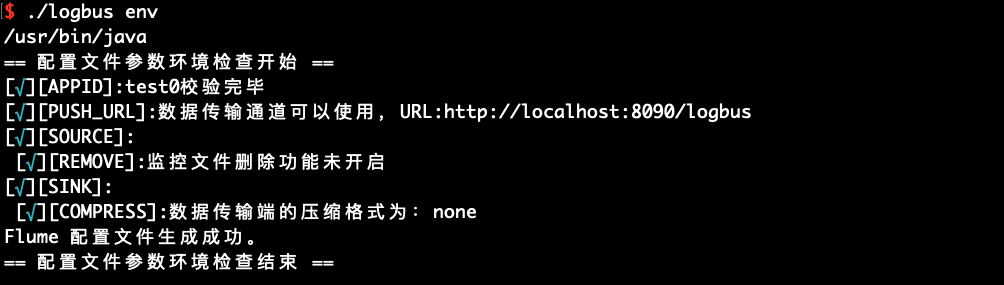
# 6.5 Start start
When you complete the format verification, data channel check and environment check, you can start LogBus to upload data. LogBus will automatically detect whether there is new data written to your file, and if there is new data, then Upload the data.
./logbus start
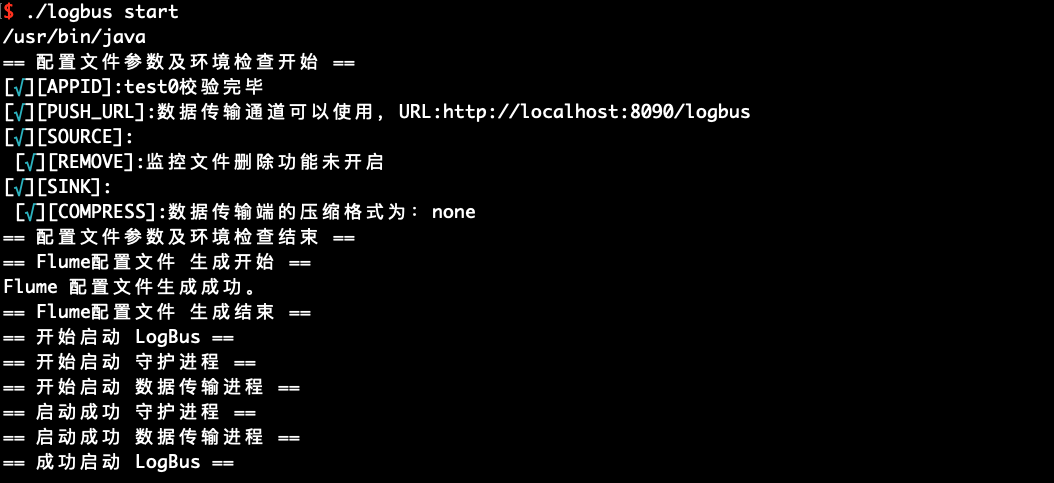
# 6.6 Stop stop
If you want to stop the LogBus, use the stop command. This command will take some time, but there will be no data loss.
./logbus stop

# 6.7 Stop stop_force
If you want to stop LogBus immediately, use the stop_force command, which may cause data loss.
./logbus stop_force
# 6.8 Restart restart
You can use the restart command to restart LogBus, which is suitable for making the new configuration take effect after modifying the configuration parameters.
./logbus restart
# 6.9 Reset reset
Using reset will reset LogBus. Please use this command carefully. Once used, the file transfer record will be cleared and LogBus will upload all data again. If you use this command under unclear conditions, it may cause duplication of your data. It is recommended to communicate with TA staff before using it.
./logbus reset
After using the reset command, you need to perform start to restart the data transfer.
After LogBus version 1.5.0, add the following confirmation message, and reset LogBus will start after confirmation.

# 6.10 View Version Number version
If you want to know the version number of the LogBus you are using, you can use the version command. If your LogBus does not have this command, the version you are using is an earlier version.
./logbus version
# 6.11 Upgrade logBus Version update
LogBus version 1.5.0, added the function of online update version, execute this command to upgrade LogBus to the latest version.
./logbus update
# 6.12 View the Current Upload progress
LogBus version 1.5.9, added the function of viewing the current upload progress, execute the command can query the current transmission progress, you can use -appid to specify the project, you can also directly add the file full pathname to specify the query.
./logbus progress /data/logbus-1.log /data/logbus-2.log -appid {APPID}
# 6.13 Check logBus FAQ doctor
LogBus version 1.5.12, a new command to check the common problems of logBus, execute this command to see if there are problems with the current logBus
./logbus doctor
# 6.14 View the Current Upload Speed and Status of logBus status
LogBus version 1.5.13, the command to view the current upload speed and status of logBus, execute this command to view the current upload speed and status of logBus
./logbus status
# ChangeLog
# Version 1.5.15.7 --- 2021/12/10
New :
- Upgrade to 2.15.0 due to an old version of log4j vulnerability
# Version 1.5.15.6 --- 2021/12/06
New :
- Add Kafka configuration items to the instance configuration
# Version 1.5.15.5 --- 2021/12/02
New:
- Kafka adds SASL verification
# Version 1.5.15.4 --- 2021/11/23
Fix:
- Fix upgrade exception bug in some cases
# Version 1.5.15.3 --- 2021/11/19
Fix:
- Fix the bug of not checking appid in some cases
# Version 1.5.15.2 --- 2021/10/15
Fix:
- Fix several issues
Optimization:
- Optimize the LogBus shutdown process
# Version 1.5.15.1 --- 2021/08/17
Fix:
- Fix some problems with Kafka source reading data
# Version 1.5.15 --- 2021/06/02
Fix:
- Fix the error problem of reading blank lines
New:
- Kafka adds support for sasl authentication verification of Huawei Cloud and Alibaba Cloud, and modifies the authentication scheme before Tencent Cloud CKafka
# Version 1.5.14.3 --- 2021/04/29
Fix:
- Fix the problem that install_logbus_jdk script cannot download jre
Optimization:
- Try to repair yourself when you are in an abnormal state
# Version 1.5.14.2 --- 2021/03/16
Fix:
- Fix the problem that some old versions failed to upgrade
# Version 1.5.14.1 --- 2021/03/03
Fix:
- Fix the problem that some old versions cannot be transmitted normally due to modification of NUMTHREAD when upgrading
- Fix the problem that when the data file is deleted and regenerated, the file is uploaded repeatedly due to the original handle not being released
# Version 1.5.14 --- 2021/02/02
Optimization:
- Optimized memory scheme, which can greatly improve the transmission speed under the condition of better network
New:
- Added configuration APPID_IN_DATA to match items based on #app_id fields in data
# Version 1.5.13.1 --- 2020/12/23
Fix:
- Updated to version 2.11.2 due to a vulnerability in the old version of jackson
# Version 1.5.13 --- 2020/11/27
Optimization:
- Optimize the progress command to specify file queries and optimize the display of copy
- Optimizing docker containers
- Optimize the concurrent modification method to facilitate the modification of the concurrent number
New:
- Add the status command to view the current upload speed and status
- Add repair_channel commands to optimize the repair channel method
# Version 1.5.12 --- 2020/08/28
Optimization:
- Ensure data reliability using MemoryChannel when the data source is Kafka
- Fix the problem that the appid cannot be removed
- Optimize the env command, comprehensively check the configuration attributes and optimize the display copy
New:
- Add Send in the specified attribute order
- Add the command to check the frequently asked questions in the logbus section doctor
- 增加#event_id 和#first_check_id
# Version 1.5.11 --- 2020/06/01
Optimization:
- Ensure data reliability using MemoryChannel when the data source is a local file
New:
- Added APP_ID that can be mapped according to the specified attributes in the data.
- Added LogBus daemon health check.
- Add flume process status monitoring.
- You can add the uuid attribute to your data.
- LogBus adds and deletes logs beyond 30 days.
- Increase inspection APP_ID.
Abandoned:
- Discard the old version of ftp transmission method.
# Version 1.5.10 --- 2020/03/31
Fix:
- Fix a bug where exact path matching fails.
Optimization:
- Upgrade fastjson version to 1.2.67 to fix deserialization and SSRF vulnerabilities.
# Version 1.5.9 --- 2020/03/25
New:
- Added custom parser.
- Added the view current transfer progress command progress.
Optimization:
- Support matching any layer of fuzzy paths in taildir mode.
- Optimize support for mac systems.
# Version 1.5.8 --- 2020/02/20
New:
- In view of the packet loss problem caused by network turbulence, a retry strategy is added.
# Version 1.5.7 --- 2020/02/13
Optimization:
- Optimize the distribution strategy of the USER data channel.
# Version 1.5.6 --- 2020/01/03
Optimization:
- Optimize the storage location of pid files and state lock files.
- Optimizing concurrency is also allowed to increase when configuring multiple projects.
- Optimize JVM parameters.
- Optimization Skips hidden files when reading local files.
New:
- Support independent JDK mode.
- The daemon adds disk usage scanning function, and the LogBus is stopped voluntarily when the disk is insufficient.
- Added data_debug function to verify detailed errors in the contents of files under the configuration directory.
- Add offset position record for kafka data source.
Abandoned:
- Discard old version format_check features.
# Version 1.5.5 --- 2019/09/23
** Optimization: **
- Optimize the JDK check script to support the verification of more than JDK 10 versions.
- Optimize internal start up sequence.
- Optimize the flume running environment to avoid environmental conflicts.
- Add download progress bar display function.
- Optimize the server level ip whitelist prompt.
# Version 1.5.4 --- 2019/06/25
** Optimization: **
- Optimize profile parameter validation logic and operating instructions.
- When the number of read files exceeds the maximum limit, add logic to automatically stop LogBus.
# Version 1.5.3.1 --- 2019/05/22
Fix:
- Fix the problem of data transmission policy when the network is unavailable. The LogBus interrupts the transmission and retries all the time.
# Version 1.5.3 --- 2019/04/25
** Optimization: **
- Optimize data transfer logic when a large number of files are transferred simultaneously
- Optimize the LogBus data transmission log, divided into two logs: info and error, which is convenient to monitor the running status of LogBus
- Upgrade basic component flume to the latest version 1.9.0
Changes:
- Add Kafka butt offset configuration: set the
kafka.consumer.auto.offset.resetparameters of Kafka, the preferred value isearliestandlatest, the default setting isearliest
# Version 1.5.2.2 --- 2019/04/10
Fix:
- Fix some system compatibility issues
- Fix the problem of the maximum number of open files
- Fixed position file anomaly in some extreme cases
# Version 1.5.2.1 --- 2019/03/29
Fix:
- Fixed LogBus running abnormally in some extreme cases
# Version 1.5.2 --- 2019/03/14
New features:
- Kafka topic supports multi-APP_ID : Use multi-APP_ID to monitor multiple Kafka topics (see the configuration of Kafka related parameters for details )
# Version 1.5.1 --- 2019/03/02
New features:
- Support https protocol : transfer address PUSH_URL parameters support https protocol
- Support sub-directory monitoring : (multi) directories in multiple sub-directories in the file monitoring (see TAIL_FILE parameter configuration for details), support through date templates and regular expressions for configuration
# Version 1.5.0 --- 2018/12/26
New features:
- Support multiple APP_ID : Support data transfer to multiple projects (multiple APP_ID) in the same LogBus, and use multiple APP_ID to monitor multiple log directories at the same time
- Support online update command : add
updatecommand, execute this command to upgrade LogBus to the latest version
** Optimization: **
- Add prompt when executing
resetcommand
# Version 1.4.3 --- 2018/11/19
New features:
- Multi-file directory monitoring : Support for monitoring multiple log directories (see the configuration of
TAIL_FILEparameters for details). At the same time, the parametersFILE_DIRandFILE_PATTERNhave been deprecated. Upgrades from older versions must configureTAIL_FILE
Changes:
- Flume monitoring is changed to a custom CustomMonitor, so no FM_PORT parameter needs to be configured (this parameter is deprecated)
** Optimization: **
- Fix the problem of detecting errors above java version 10
# Version 1.4.2 --- 2018/09/03
New features:
- New data transmission method : new ftp transmission method
# Version 1.4.0 --- 2018/07/30
New features:
- Multiple instances : Multiple LogBus can be deployed on the same server.
Just install multiple LogBus tools, place them in different directories, and configure their own configuration files for each LogBus.
- Multi-threaded transmission : realize multi-threaded safety.
Set the number of threads by modifying the parameter NUMTHREAD in the configuration file
- Sink supports multiple compression formats : gzip, lz4, lzo, snappy, and none
The compression method is from left to right, and the compression ratio decreases in turn. Please choose according to the network environment and server performance.
Changes:
- After starting or modifying the configuration file for the first time, you need to call the
envcommand to make the configuration file take effect in order for LogBus to work properly.
** Optimization: **
- Optimize the check prompt copy before starting.
# Version 1.3.5 --- 2018/07/18
Optimization:
- Optimize file format check command output prompt.
- Optimize file transfer prompt output.
- Checkpoint adds a backup content to prevent frequent read and write errors at checkpoint.
- Increase channel water level control so that no channel full warning will appear.
- Add sink network socktimeout, set to 60s.
- Add LogBus monitoring, automatic restart when sink stuck.
# Version 1.3.4 --- 2018/06/08
Changes:
- Data filtering: Filter only blank lines and non-json data.
- The file deletion function has changed from the original fixed-point deletion every day to deletion every once in a while.
Configuration file:
- Configuration file format optimization, mainly classifies the configuration file into four parts: source, channel, sink and others.
- Add FREQUENCY_REMOVE parameter to delete uploaded directory files at regular intervals in minutes.
- Remove TIME_REMOVE parameters.
New features:
- Add automation tools (mainly for ansible) to start the optimization script, placed in the bin/automation directory, mainly start
start, stopstop, immediately stopstop_atOncethree commands.
Performance optimization:
- Optimize the memory required for startup and reduce memory requirements.
# Version 1.3 --- 2018/04/21
- Added support for Kafka data sources
- Fixed known bugs
# Version 1.0 --- 2018/03/29
- LogBus Release